Turn Your Datacenter
into an AI Factory
Deliver high-performance, production LLM inference using OpenAI-compatible APIs—powered by specialized hardware, deeply optimized software, and data-center co-design tuned for maximum efficiency and throughput—all within your own infrastructure.
From GPU Capacity to
AI Revenue
Many datacenters have GPU capacity and growing demand. What's missing is a reliable way to turn that capacity into a sellable service with predictable performance and economics.
AI demand is rising, revenue is not
GPU capacity alone does not translate into revenue. Without the right serving stack and pricing model, utilization stays uneven and margins remain unclear.
Production workloads are hard to operate
These workloads require low latency, high concurrency, and predictable behavior. Ad-hoc deployments and generic stacks struggle under real production traffic.
Most platforms are someone else's cloud
Many providers sell access to their own infrastructure. Datacenters lose control over pricing, branding, and customer relationships.
CloudRift helps datacenter operators close this gap
By combining production software, benchmark-driven hardware guidance, and operational experience from running real datacenters at scale.
Run Enterprise LLMs on
Your Own GPUs
CloudRift enables organizations—from datacenter operators to enterprises with on-prem infrastructure—to offer production-grade LLM-as-a-service, running on their own hardware and delivered through enterprise-ready APIs.
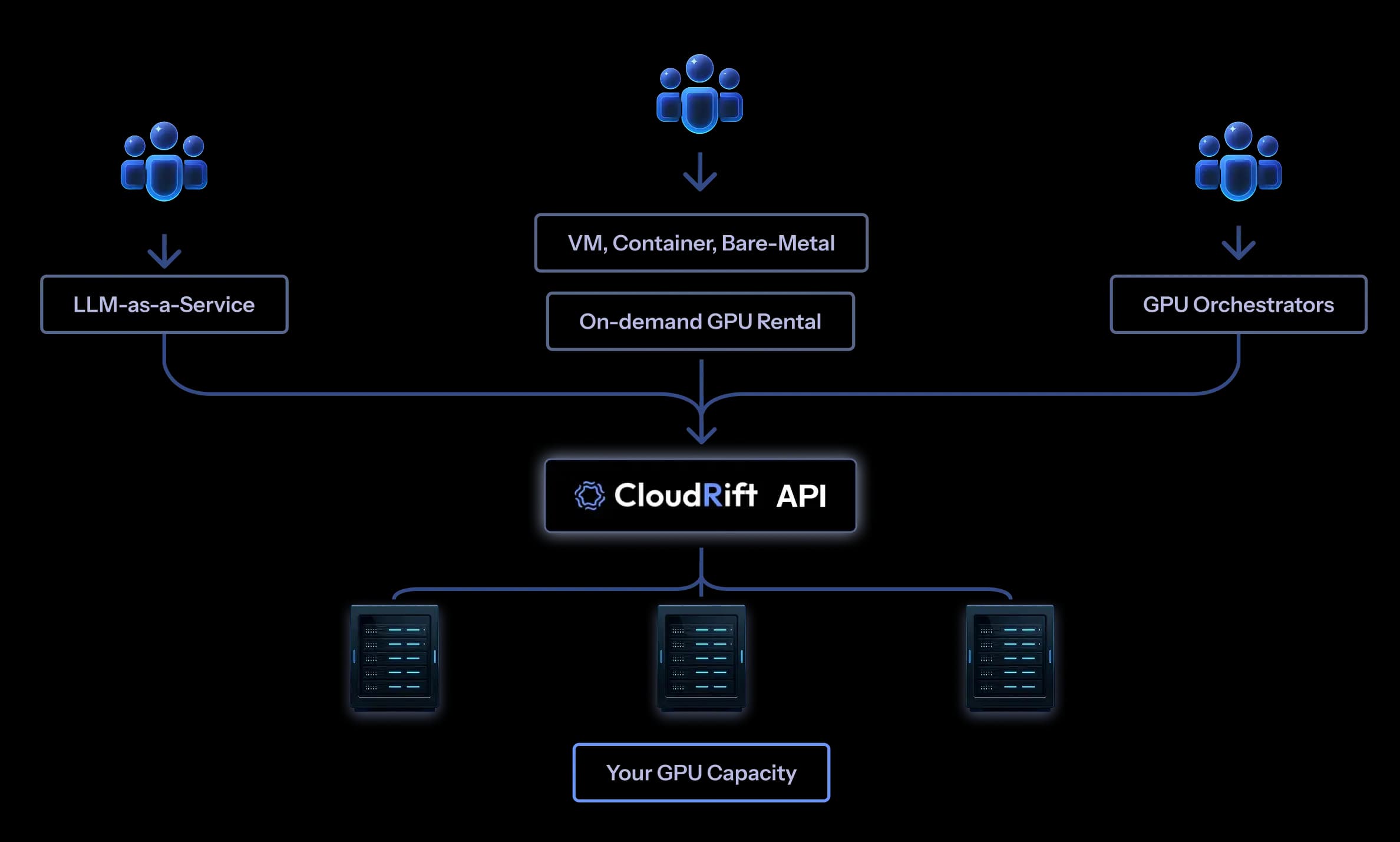
Production LLM-as-a-Service Software
OpenAI-compatible APIs, streaming support, and usage-based billing designed for real production workloads.
Data-Driven Hardware Decisions
Real-world benchmarks and performance data guide GPU selection, configuration, and deployment strategy.
Built by Experts
Designed and operated by teams with deep experience in model optimization and datacenter operation.
How It Works
1
Benchmark and Plan
Benchmark workloads across GPUs and configurations to define performance targets and hardware requirements.
2
Procure Hardware & Build
Connect with trusted build partners for hardware procurement and deployment. We help with vendor relationships, financing options, and ensuring your hardware matches benchmark-driven specifications.
3
Deploy the Stack
Deploy a production stack optimized for throughput, latency, and concurrency.
4
Expose APIs
Deliver via OpenAI-compatible APIs with streaming and usage-based billing.
5
Operate and Optimize
Monitor performance, adjust configurations, and optimize cost and utilization over time.
Hardware Acceleration: We can install and configure specialized accelerator hardware for your datacenter when additional performance optimization is needed.
Benchmark-Driven Hardware Guidance
Inference performance depends heavily on hardware choice and configuration. CloudRift runs regular benchmarks across GPUs, models, and serving setups to understand real-world tradeoffs.
Why Our Benchmarks Matter
Synthetic specs do not reflect real production behavior. We measure complete serving paths under realistic load.
What We Benchmark
Models, GPU generations, throughput, latency, concurrency, cost efficiency, different context lengths, parallelization parameters, and inference frameworks.
How Operators Use This Data
To choose hardware, tune deployments, and define pricing models for services.

Real-world benchmark: Qwen3-Coder-480B-A35B-Instruct-AWQ tested on 8x RTX Pro 6000, 8x H100, and 8x H200 GPU configurations
Inference Accelerators
and Hardware Optimization
Some workloads require more than standard GPU configurations. CloudRift supports deeper hardware and system-level optimizations for demanding use cases.

Accelerator Options
For select deployments, we support specialized accelerators designed to improve throughput and reduce latency by optimizing memory access and model serving paths.
- Faster KV cache access
- Reduced memory bottlenecks
- Better performance under high concurrency

System and Rack-Level Optimization
Beyond individual components, CloudRift helps operators optimize their systems, including GPU density, storage layout, and network configuration.
- Hardware-aware serving configurations
- Balanced GPU, memory, and I/O
- Designs aligned with benchmark data
Enterprise Use Cases
CloudRift supports workloads with strict requirements around latency, throughput, and reliability. These deployments typically serve large user bases, downstream systems, or customer-facing products.
Telecom and Network Services
Inference workloads supporting customer interaction, network optimization, and real-time decision systems. These use cases prioritize predictable latency and high concurrency across distributed environments.
Large-Scale AI Applications
Customer-facing AI systems such as chat interfaces, content generation, or search augmentation. These workloads demand throughput, reliability, and efficient scaling under peak traffic.
Banks and Financial Services
Workloads for fraud detection, customer service automation, document processing, and risk analysis. These use cases demand high reliability, data security, and regulatory compliance with predictable performance.
Internal Enterprise AI Systems
AI models used internally for automation, analytics, or support tooling, where reliability and data locality matter as much as performance.
Why Datacenter Operators Choose CloudRift
CloudRift supports workloads with strict requirements around latency, throughput, and reliability. These deployments typically serve large user bases, downstream systems, or customer-facing products.
Infrastructure Ownership
Everything runs on your hardware, in your datacenters. You control capacity, deployment models, and physical constraints.
Customer and Pricing Control
You set pricing, billing models, and customer relationships. CloudRift does not sit between you and your customers.
Commercial Model
Designed for operators who want to offer AI as a service, not enterprises looking to consume someone else's cloud.
Operational Depth
CloudRift is built by teams who manage datacenters at scale. We design inference systems with operational realities in mind, not just API performance.
Hardware Flexibility
We support multiple GPU generations and configurations and help select hardware based on real benchmarks, not fixed product tiers.
Trusted byInfrastructure Partners
Our platform powers GPU infrastructure for leading providers worldwide. Here are some of our partners.
Katzteleport
Region: Central Asia
Kazteleport is a leading Kazakhstan-based provider of IT, communications, and cloud services with 20+ years of serving mid-market and enterprise customers. The company is expanding across Central Asia with its SmartCloud platform and new facilities in Uzbekistan. Kazteleport uses CloudRift to power its GPU cloud, gpu.kazteleport.kz serving H100 and B200.
Customers include Halyk Bank, the largest bank in Central Asia, and other prominent regional enterprises. CloudRift manages private GPU infrastructure for analytics workloads at Halyk Bank and public GPU infrastructure for Kazteleport's other clients.
Years of Experience in
Model Deployment & Optimization
Our team has deep expertise in production inference workloads, from deployment to optimization at scale.

Animoji
Real-time facial tracking

ARKit
Spatial computing

Hand Tracking
Vision Pro gestures
Portrait Mode
Depth sensing & bokeh

Roblox Face Tracking
Live avatar animation
.webp&w=3840&q=75)
Room Plan
3D space scanning

AI Texture Generation
Procedural asset creation

Hand Tracking
Gesture recognition
FAQ
Common questions about running inference with CloudRift
CloudRift runs on your existing GPU infrastructure in your datacenters. You need GPU-enabled servers (consumer or enterprise GPUs), standard networking, and the ability to install our software stack. We support a wide range of GPU models and configurations.
Performance guarantees and SLAs are defined by you based on your infrastructure capabilities and customer requirements. CloudRift provides the tools and monitoring to help you meet your commitments, but you maintain control over SLAs and customer relationships.
Yes. CloudRift enables you to offer services under your own brand with full control over pricing, billing models, and customer relationships. We provide the platform and tools; you own the customer experience and commercial terms.
Most deployments reach production within a few days to a few weeks, depending on your infrastructure setup and requirements. We help with benchmarking, deployment, configuration, and validation to get you operational quickly.
Yes. We provide benchmark-driven hardware guidance based on real-world performance data. Our benchmarks help you select GPUs, configurations, and deployment strategies optimized for your specific inference workloads and performance targets.
Yes. Beyond the platform, we offer advisory services including hardware selection guidance, deployment strategy, performance optimization, and operational best practices based on our experience running datacenters at scale.
Get in Touch
We're here to support your compute and AI needs. Let us know if you're looking to:
- Find an affordable GPU provider
- Sell your compute online
- Manage on-prem infrastructure
- Build a hybrid cloud solution
- Optimize your AI deployment
hello@cloudrift.ai
CloudRift Inc., a Delaware corporation
PO Box 1224, Santa Clara, CA 95052, USA
+1 (831) 534-3437
PO Box 1224, Santa Clara, CA 95052, USA
+1 (831) 534-3437