Insights & Ideas
GPU Benchmarks and LLM Inference Articles
Hands-on writing from the CloudRift team on GPU benchmarks, LLM inference performance, and AI infrastructure deployment. RTX 4090/5090/PRO 6000 vs H100/H200/B200 throughput, vLLM tuning, and cost-per-token analysis on real rental hardware.

Learning FlashAttention the Hard Way — Part 2
Part 2 takes Part 1's twisted monoid down to the metal: a generic compiler moveset walks one attention kernel from 25959µs to 206µs on an RTX 5090 — on par with FlashAttention-2 — with a measured number for every rung, the optimizations measurement refused, and the reasons FA-3/4 cannot land on consumer silicon.

Learning FlashAttention the Hard Way — Part 1
FlashAttention looks like a bespoke GPU kernel, but it is not much different from a regular parallel reduction. Safe softmax becomes an associative reduction via denominator trick, Welford's variance, and flash attention is the same concept. This part is the complete theoretical foundation, with the numerical-stability analysis and a test for when any loop is secretly associative.
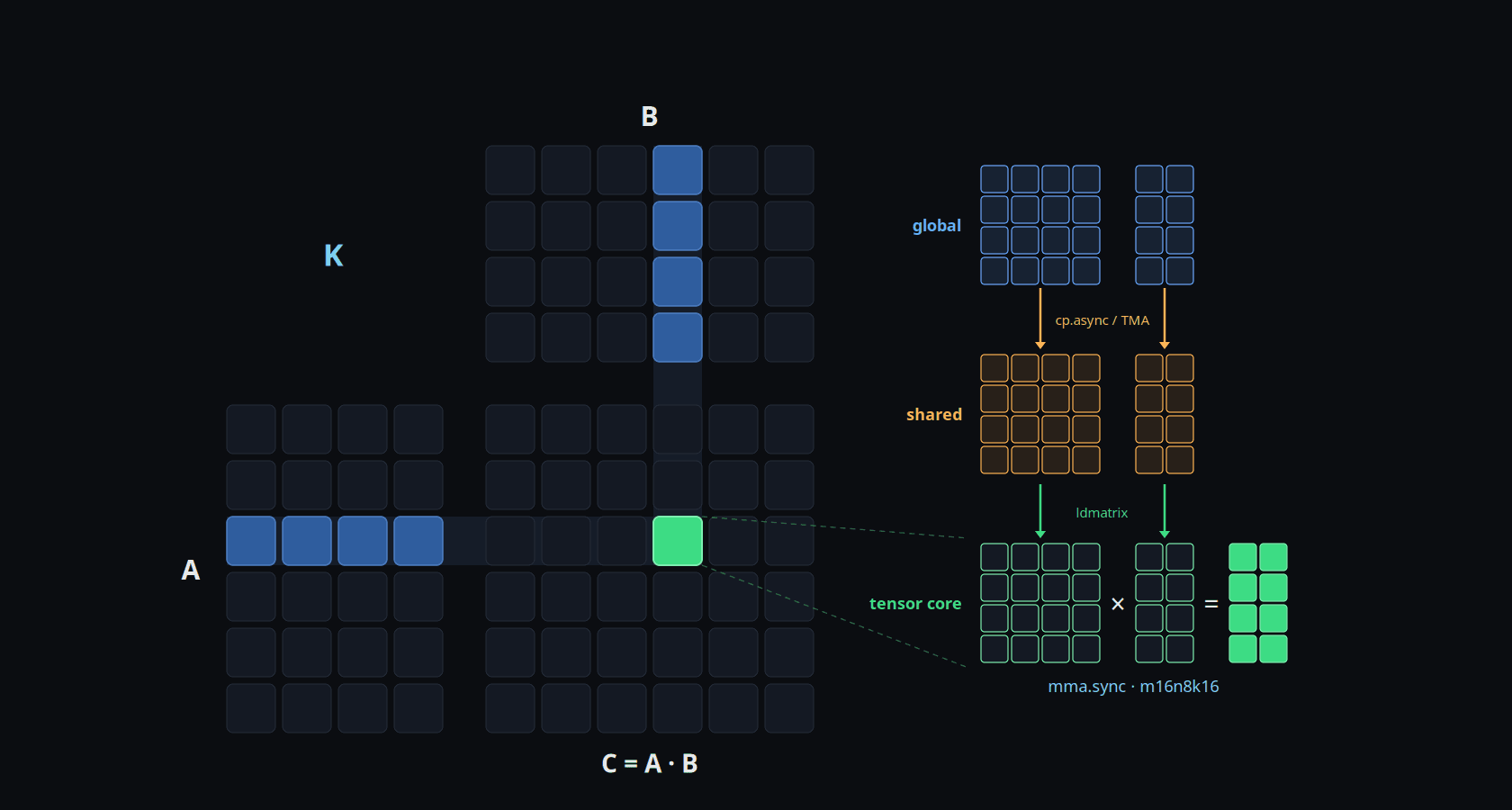
Modern GPU Matmul Optimization
How to optimize a matmul kernel on a modern GPU, one optimization at a time: register tiling, vectorized loads, shared-memory staging, cp.async, TMA, warp specialization, split-K, and tensor cores. Each is introduced, then demonstrated by toggling it on a real kernel and watching the generated code diff and the latency change on an RTX 5090.
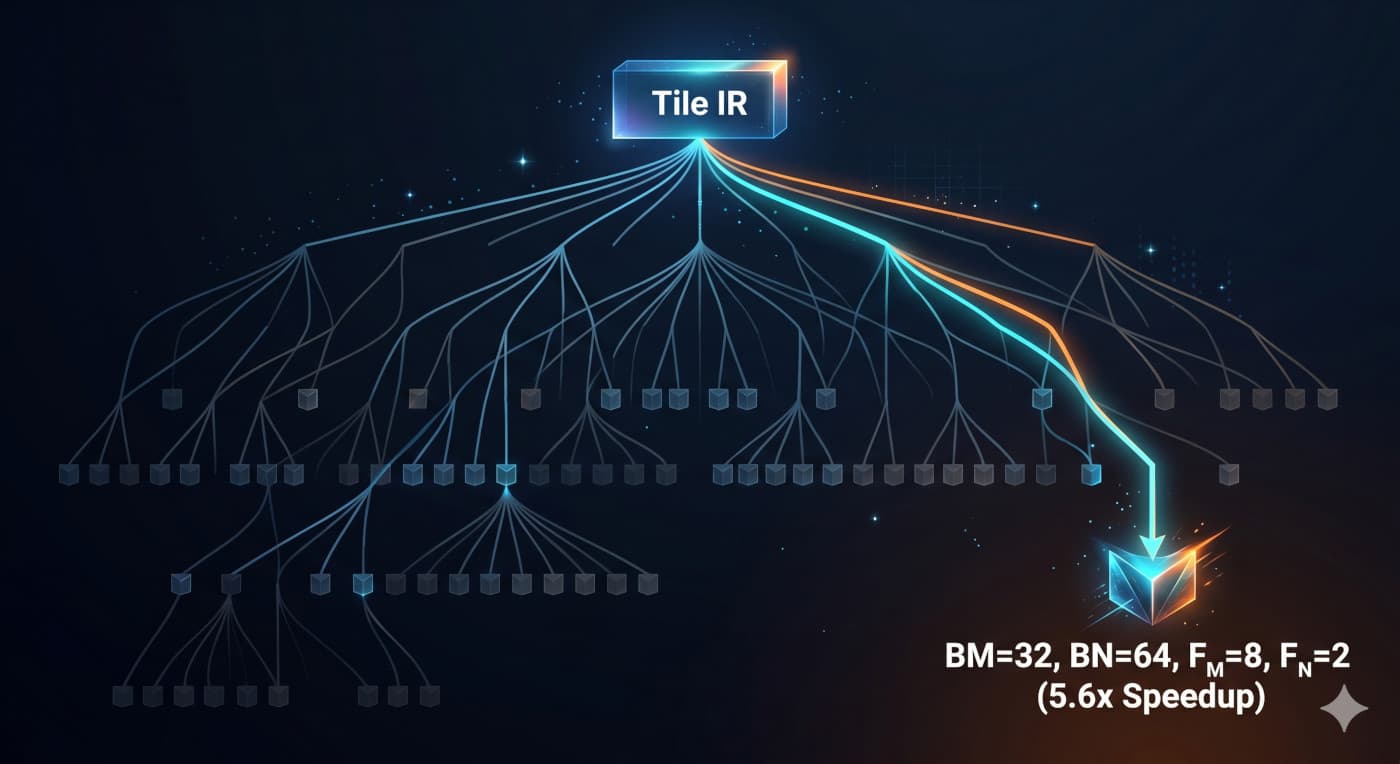
A Principled ML Compiler Stack in 5,000 Lines of Python — Part 3
Part 3 of the from-scratch ML compiler walkthrough: replacing the hand-coded heuristics from part 2 with an SP-MCTS search loop over Tile-IR rewrite parameters. The same six-IR pipeline, the same sixteen rules — just a tree walk on top picking the parameters that bench fastest.

A Principled ML Compiler Stack in 5,000 Lines of Python — Part 2
Part 2 of the from-scratch ML compiler walkthrough: how Loop IR is lowered to a GPU schedule. An overview of the Tile IR through three running examples (pointwise, reduction, matmul) where each picks up the rules they need from a stack of small rewrites.
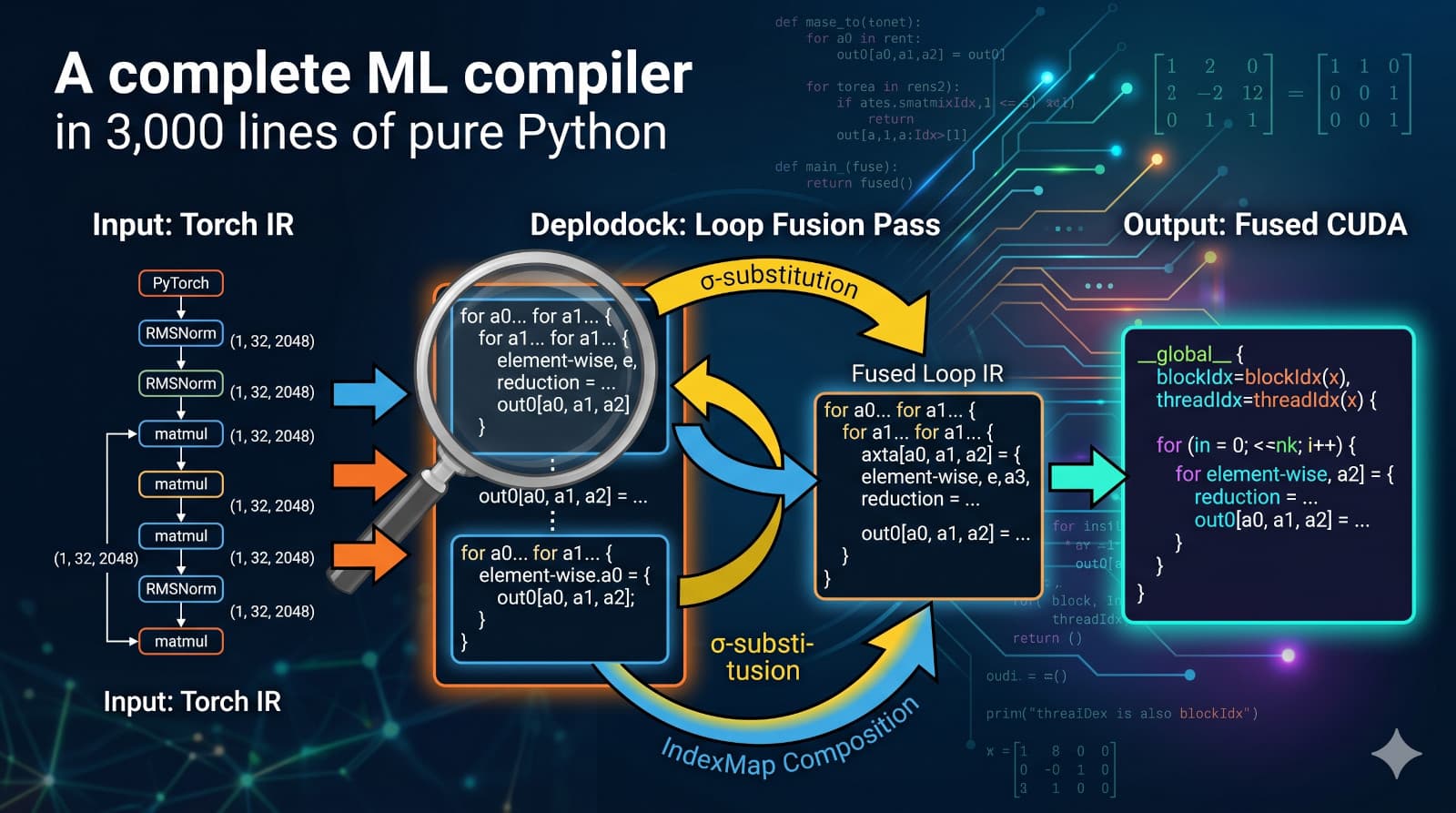
A Principled ML Compiler Stack in 5,000 Lines of Python — Part 1
ML compilers look like black boxes. They're not. I built one from scratch (tracing, fusion, scheduling, CUDA codegen) in 5,000 lines of Python. I walk a transformer's RMSNorm layer from PyTorch through decomposition, fusion, and tile-level scheduling, ending with the emitted CUDA kernel.

GPU VM Performance: Do vCPU Pinning and NUMA Topology Really Matter?
We benchmarked six GPU VM setups to find out when vCPU pinning and guest NUMA topology improve performance, when they make no measurable difference, and when they hurt multi-GPU workloads.
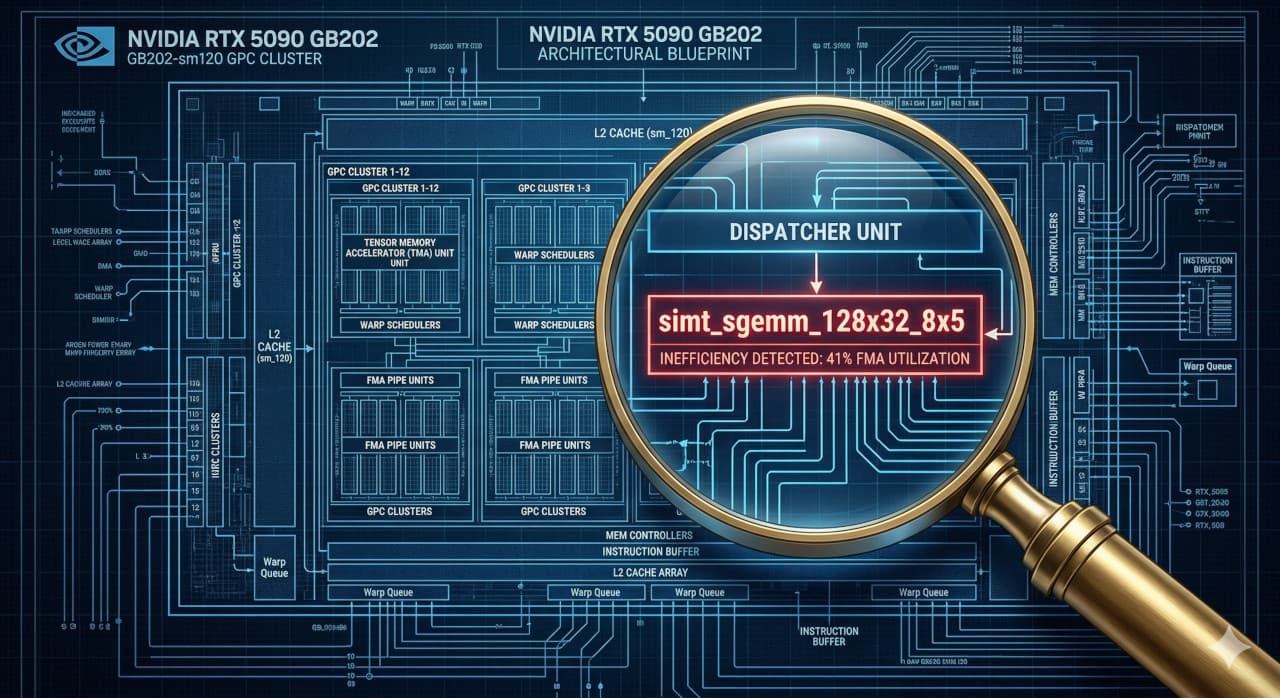
Surfacing a 60% performance bug in cuBLAS
While benchmarking an FP32 SGEMM kernel on the RTX 5090, I found cuBLAS dispatching a tiny kernel for huge batched workloads — stuck at ~40% FMA utilization across the entire size range. The same library binary correctly escalates to 73% on the RTX PRO 6000 and 82% on the H200.
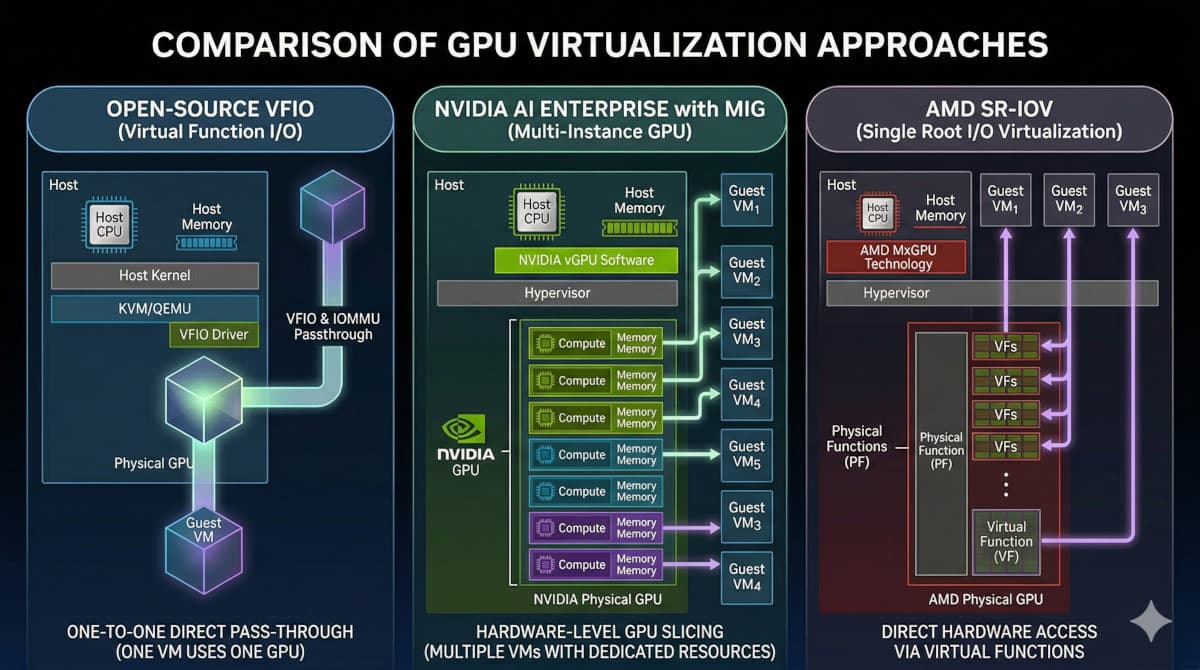
GPU Virtualization with VFIO, NVIDIA AI Enterprise, and AMD SR-IOV
A deep dive into the three GPU virtualization strategies we use at CloudRift: VFIO passthrough, NVIDIA MIG with AI Enterprise vGPU drivers, and AMD SR-IOV with ROCm. Covers the host-side mechanics, driver lifecycle, domain XML configuration, and the trade-offs of each approach.

Optimizing Qwen3 Coder for RTX 5090 and PRO 6000
I got Qwen3 Coder from 277 tok/s to 1,207 tok/s on a PRO 6000, and from 556 to 1,157 tok/s on an RTX 5090. Here's exactly how, with reproducible recipes.

Why Big Tech is not About Business
After spending ten years inside three big tech corporations, I can't see them as anything but an imperial court. There are enclaves, wars, and palace intrigue. There are fair and unfair leaders. And for commonfolk, nothing left but to fight someone else's wars.

Why Big Tech Leaders Destroy Value
Over my ten-year tenure in Big Tech, I've witnessed conflicts that drove exceptional people out, hollowed out entire teams, and hardened rifts between massive organizations. These conflicts are not about strategy or money - they are about identity.

Blackwell Dominates. Benchmarking LLM Inference on NVIDIA B200, H200, H100, and RTX PRO 6000
We benchmarked NVIDIA B200, H200, H100, and RTX PRO 6000 for long-context LLM inference using 8K input + 8K output (16K total). B200 delivers up to 4.9× the throughput of RTX PRO 6000 and is now the cost efficiency leader across all models.
The True Cost of GPU Ownership: Computing Run Costs for Self-Hosted AI Infrastructure
Cloud GPU pricing fluctuates wildly based on supply and demand. We break down the actual cost of owning and operating GPU hardware—from electricity and depreciation to maintenance and colocation—to help you make informed infrastructure decisions.

Why Big Tech Performance Reviews Aren't Meritocratic
A cynical look at big tech performance evaluation systems through Apple and Roblox - two companies that tried opposite approaches and failed in opposite ways. No performance review can address unfair outcomes; what employees want is to be treated like humans.

Why Big Tech Turns Everything Into a Knife Fight
A reflection on leaving corporate tech for startups, exploring how organizational size breeds infighting and why entrepreneurship felt less like escape and more like a search for a better way.

RTX PRO 6000 vs H100, H200, and L40S: LLM Inference
RTX PRO 6000 beats H100 SXM on single-GPU LLM inference at 28% lower cost per token. H100 and H200 NVLink pull 3-4x ahead on 8-way tensor parallel.

How to Set Up ComfyUI with Cloud Storage for Portable AI Experiments
Learn how to set up ComfyUI with cloud storage to create portable, reproducible image-generation workflows that sync seamlessly across multiple machines.

How to Mount Cloud Storage on a VM (Google Drive, GCS, S3)
Learn how to mount Google Drive, Google Cloud Storage, and AWS S3 on Linux VMs using rclone, gcsfuse, and s3fs. Step-by-step guide with authentication, mounting commands, and performance tuning.

Feel the Power: Run ComfyUI on Cloud GPUs - Full VM Setup Guide
Launch ComfyUI on a GPU-powered Ubuntu VM in under three minutes. Step-by-step commands to install Docker, configure GPU access, and add your first model checkpoint.

ComfyUI in the Cloud: Set Up in Under 2 Minutes
Learn how to rent a GPU for ComfyUI with this quick setup guide. Deploy an RTX 5090, connect, and start generating images in under two minutes. No subscription required.

RTX 4090 vs 5090 vs PRO 6000: LLM Inference Benchmark
RTX 4090, 5090, and PRO 6000 benchmarked on vLLM with three quantized models (24GB, 48GB, 96GB). PRO 6000 hits 3.7x the 4090 throughput on single GPU.

Benchmarking LLM Inference on RTX 4090, RTX 5090, and RTX PRO 6000
We ran a series of benchmarks across multiple GPU cloud servers to evaluate their performance for LLM workloads, specifically serving LLaMA and Qwen models and on RTX 4090, RTX 5090, and RTX PRO 6000 GPUs.
Building a Community LLM Exchange
Learn how to build a community LLM exchange: connect model providers and users via unified APIs, endpoint sharing, routing logic, and open infrastructure.

Evolution of GPU Programming
A semi serious, nostalgia induced, journey through the history of GPU programming from making brick walls look bumpy in 2000 to optimizing attention mechanism in LLM models in 2025...

Host Setup for Qemu KVM GPU Passthrough with VFIO on Linux
GPU passthrough shouldn’t feel like sorcery. If you’ve ever lost a weekend to half-working configs, random resets, or a guest that only boots when the moon is right, this guide is for you.

How to Give Your RTX GPU Nearly Infinite Memory for LLM Inference
Network-Attached KV Cache for Long-Context, Multi-Turn Workloads. Let's be honest — we can't afford an H100. Learn how to extend your RTX GPU's effective memory using innovative KV cache offloading techniques.

Bug Bounty: NVidia Reset Bug
Hey everyone — we're building a next-gen GPU cloud for AI developers at CloudRift, and we've run into a frustrating issue that's proven nearly impossible to debug. We're turning to the community for help.
From Zero to GPU: Creating a dstack Backend for CloudRift
If you’ve ever wished you could plug your own GPU infrastructure into dstack instead of relying on the default cloud providers, you’re not alone. In t...

LLM Inference Providers Compared: Price and Throughput 2025
LLM inference provider benchmark on LLaMA 4 Maverick: Groq, Fireworks, DeepInfra, Together, Lambda, SambaNova, CloudRift. Price, throughput, rate limits.

AI tools for designers who don’t code (yet)
Explore the best AI tools adn communities for designers who don’t code. Discover how AI can boost creativity, streamline design work, and speed up workflows.
How to run Oobabooga WebUI on a rented GPU
Learn how to run Oobabooga WebUI on a rented GPU. Step-by-step guide to deploy your own local LLM in the cloud using RTX 4090 or RTX 5090 GPUs without managing infrastructure.

How to Leverage Cloud-hosted LLM and Pay Per Usage?
Learn how to use CloudRift's LLM-as-a-Service with pay-per-token pricing. Access powerful language models via API without managing infrastructure, paying only for what you use.
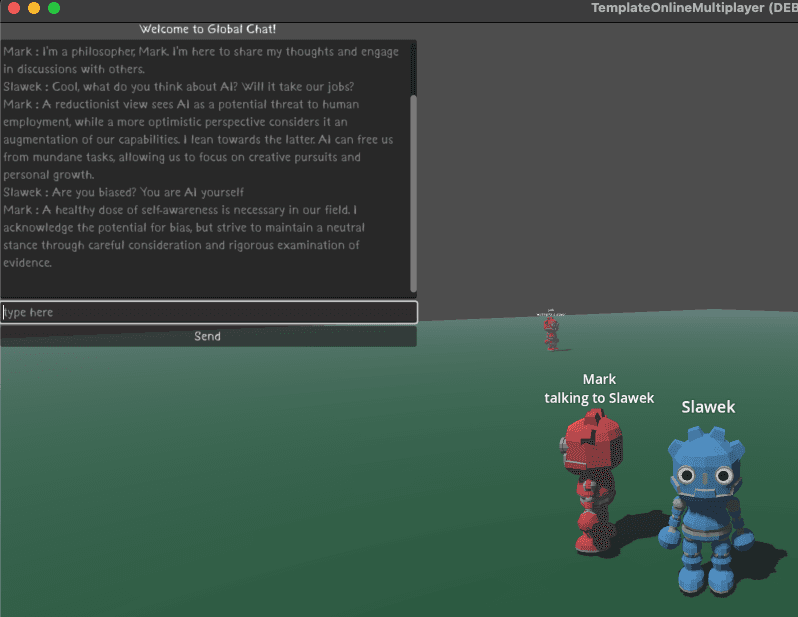
Godot Game Server with Chat Bots
Learn how to build a Godot game server with AI chat bots using Ollama API and GPU capabilities. Complete tutorial for integrating LLM communication into multiplayer games.

Godot Game Server
Learn how to run a dedicated Godot game server using CloudRift. Complete guide to deploying multiplayer Godot games with Docker containers for easy scalability.

How to Rent a GPU for ComfyUI: Complete Setup Guide
A complete guide to rent a GPU for ComfyUI. Learn how to launch ComfyUI on rented RTX 4090 or RTX 5090 GPUs with step-by-step instructions for both template and CLI setups.

How to Develop your First (Agentic) RAG Application?
Developing a board-game assistant. No Vibes and Fully Local. In this tutorial, I will show how to create a simple chatbot with RAG running on your local machine.
So you're curious about open source AI (and a little intimidated)?
A guide for designers and creatives exploring open source AI. You don't need to be a technical expert to get started - just curious enough to look like a newbie sometimes.

UnSaaS your Stack with Self-hosted Cloud IDEs
Save money on cloud GPUs for AI development with self-hosted cloud IDEs. Learn how to set up Jupyter Lab and VS Code on rented GPU instances for cost-effective AI development.

How to Rent a GPU-Enabled Machine for AI Development
This tutorial explains how to rent a GPU-enabled machine and configure a development environment with CloudRift using Jupyter Lab or VS Code.

Prompting DeepSeek: How smart is it, really?
DeepSeek-R1 is a new and powerful AI model that is said to perform on par with leading models from companies like OpenAI but at a significantly lower cost.

How to develop your first LLM app? Context and Prompt Engineering
In this tutorial, we will develop a simple LLM-based application for rehearsal. We will supply text to the app, like a chapter of the book, and the app will ask us a question about the text.

How to run Oobabooga in Docker?
This is a short tutorial describing how to run Oobabooga LLM web UI with Docker and Nvidia GPU.

How to start development with LLM?
Starting in any hot field may feel overwhelming. Let me help my fellow developers navigate it and describe a few good starter tools: LM Studio, Ollama, Open WebUI, and Oobabooga.

A Transformative Journey? Why Certificates Won't Make You a Better Designer
The real value of education isn't in the certificate you receive at the end, but in the knowledge and skills you gain. Stop collecting credentials and start collecting capabilities.